Our Nomad jobs are getting restarted whenever a linked vault key is updated, which is the desired behaviour. I am looking for some info how can we better control the restarts. We have 8 instances in a job and if all 8 restart at the same time, we experience and outage for about 5-6 seconds (the time it takes for the allocs to restart).
Can the update or restart stanza be useful here? Asking as I could not find anything in the docs.
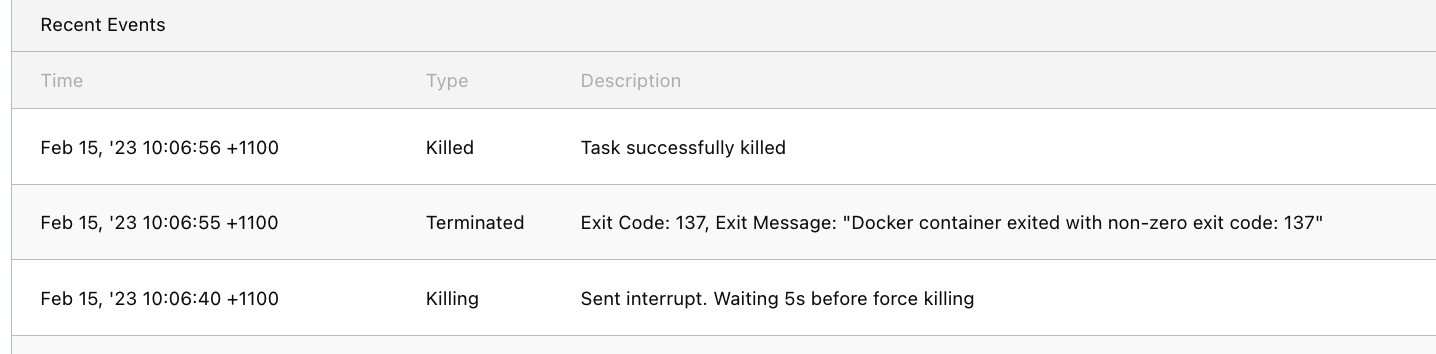
@jrasell we have noticed that while splay helped with spreading out the restarts, it does not solve the outage problem entirely. The concerned application is a webapp that uses consul service discovery + traefik ingress. When an allocation restarts it’s not removed from the consul catalog and hence traefik keeps sending requests to it while the alloc is being restarted (takes about 10-15 seconds during which the app returns 502 errors).
I wonder if there’s a way to remove the alloc from consul before Nomad kills it.
The deployment process does exactly that hence we see no 502 responses during deployments.
I have noticed that the cli cmd nomad alloc stop xxxx also removes the service from consul so that works too.
Just wanted to confirm with you if it’s possible with Nomad currently or do we need to build something custom to handle the template updates.
Do the services have attached checks? If not, this would be an addition I would look into as Traefik should remove services from its routing table that are unhealthy.
I just took a look into the code, and it seems there is a difference between services blocks at the task level or group level. I wonder if you could try moving your service blocks to the task level, and whether this helps your current situation?
Perhaps a solution could be to add stop as an option to change_mode. Which would shutting down of the alloc and allow for graceful handling of template changes.