We have rest api which is talking to few gRPC services.
Since we moved to service mesh, we are getting few errors
- “failed to connect to all addresses; last error: INTERNAL: Trying to connect an http1.x server”
- “BadHttpMessage:400, message='Pause on PRI/Upgrade”
Strange part is that it looks like this errors are random, as sometimes requests are working and sometime they fail.
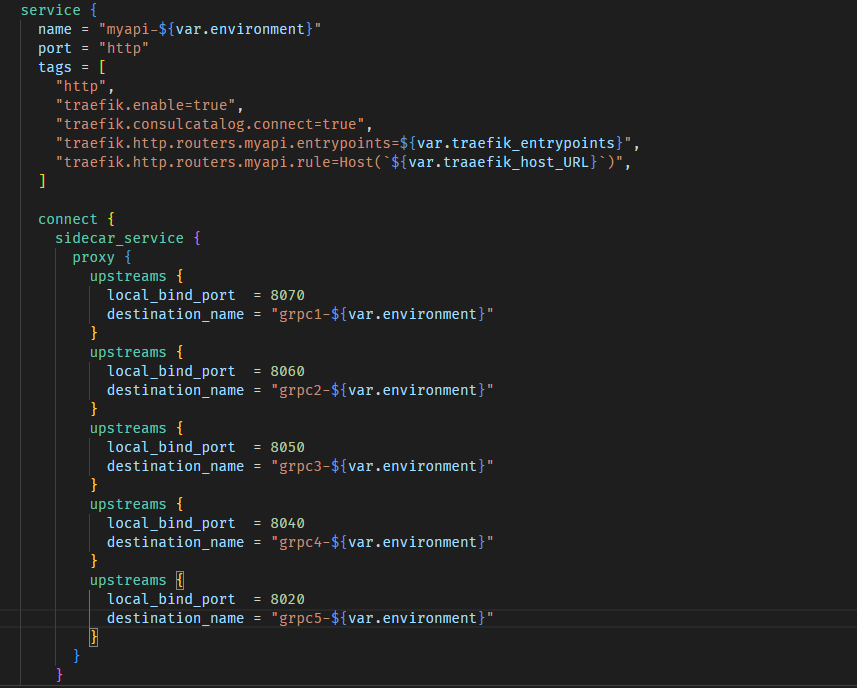
Rest api is exposed via traefik, and relevant nomad.hcl looks like this.
Not even sure where to start with troubleshooting as it seems it is happening randomly.
Does any1 have any idea?
I am not sure what your configuration scenario is, it is not clear to me. Are you using Traefik for the ingress (north-south) and Consul Service Mesh for east-west?
Within the service mesh, are you using multiple gRPC ports per service? If a service is using multiple ports, the transparent-proxy will be turned off, which adds some layers of complexity. If a service only supports a single gRPC port, then transparent proxy is turned on, and this should work, but the ingress controller pods will need to be integrated into the mesh, so that traffic can be sent to service mesh members.
Thnx for post.
Yes we are using traefik for ingress, and mesh for internal stuff.
REST API in question is using more then one gRPC services.
I put some screenshots in original post so I hope it makes things more clear.
This is just generic advice for any ingress controller. Traefik may have some extra specific integration, but I have yet to play with this.
Consul Service Mesh really only truly supports a single port service, for multiple ports from a single service, there are some challenges:
- each port specified in the
service resource must be broken up into separate services, one port per service.
- transparent-proxy can longer be used, so you will need to do the following:
- specify the services supported listed in the
consul.hashicorp.com/connect-service annotation on the deployment (or daemonset, staticset, replicaset, or pod) specification.
- clients within the mesh (which would be the ingress controller) will need to specify
consul.hashicorp.com/connect-service-upstreams annotation. This would include the ingress controller that should have proxy side car injected.
- if ACLs are used, then you also need to do the following:
- specify
servicedefault and intention to allow traffic through the mesh tunnel.
- the ingress-controller will have to route through
localhost to use the mesh.
- anything landing connect to the service through one of the
service endpoints, will not go through the mesh, and thus the service is open up and insecure, and policies (intentions) will no longer work for multi-port.
For the ingress-controller, I am not sure how to force it to go through localhost instead of what it does naturally through service end point (which is now ingresses work). With nginx based ingress controllers, there should be some way to inject custom nginx.conf into LB, so one way would be maybe to see how the ingress is rendered into a configuration on the server, then copypasta that by replace all outbound myservice.svc.cluster.local to localhost. For Traefik, I am not sure how that can be done.
I saw this article, and I am not sure if it captures the use case. I found this blog on Traefik integration.
I notice this is a single-port example without ACLs, so not sure how useful that is.
Thank you for help, it seems that problem was much simpler, we had 2 services which were using same service name, one of them was gRPC but other wasn’t.
Last night while I was checking consul I noticed that service which has count=1 in nomad.hcl was showing in consul with 7 instances in service mesh.
So I did some digging and found that other service is using same name.
Fixed that and life is good again.