IMO, that makes their very name a false promise, and I can’t imagine why Vault was designed that way.
But, all recovery keys are useful for, is for a quorum of Vault administrators to prove to the Vault software that they have a quorum, to authenticate operations which require that.
In your situation, you need to reconfigure cluster B to use cluster A’s transit autounseal configuration.
(And then, if desired, follow the seal migration process on cluster B.)
Thanks for your inputs. I tried reconfiguring cluster B to using cluster A’s transit autounseal configuration but same error.
Steps:
copied transit server ‘data’ directory from Cluster A to Cluster B and brought up the server in Cluster B.
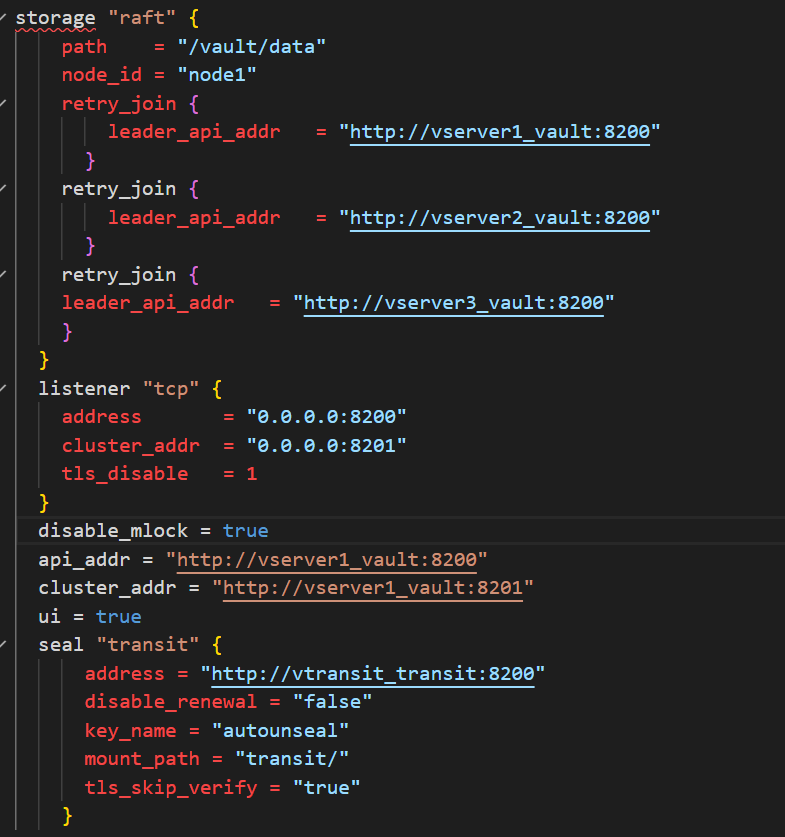
Transit server config used to bring up Cluster A:
storage “file” {
path = “/vault/data”
node_id = “node1”
}
listener “tcp” {
address = “0.0.0.0:8200”
tls_disable = true
}
disable_mlock = true
------- Script to start and generate token-----------
------Below executed on Cluster A and Cluster B in one vault server (initial leader) --------
vault operator init -recovery-shares=5 -recovery-threshold=5 > /vault/data/recovery-key.txt
Verified all the vault server were up( auto-unseald).
Copied this data directory of transit server from cluster A to Cluster B so that it will not initialize again and can be brought up with old token and configuration.
I think that to make progress here you need to look at the errors being returned from vtransit_transit - the ones which are cut off and not included in your original message:
The simplest way around this is to migrate to shamir first, then do your backup and restore. When you have auto-unseal your keys are no longer “unseal keys” they are “recovery keys” for cluster recovery, not for the assembling the encryption key that Vault needs. Moving back to shamir, you’ll end up with “unseal keys” again.
There are more complicated steps you can go through to do this, but I think this is the fastest method. A safer method does exist but it does require an Enterprise license.