Hi,
Nomad version - 1.3.4
We are seeing increasing times to deploy jobs to a Nomad cluster. The time has gone up significantly.
It’s the same outcome with spread or binpack Scheduling algorithm. There’s approximately 30s between the client receiving the task and building the task Dir. (attached screenshot)
And with 25 Allocations in a deployment, it causes the deployment to run for 12 minutes longer than it should.
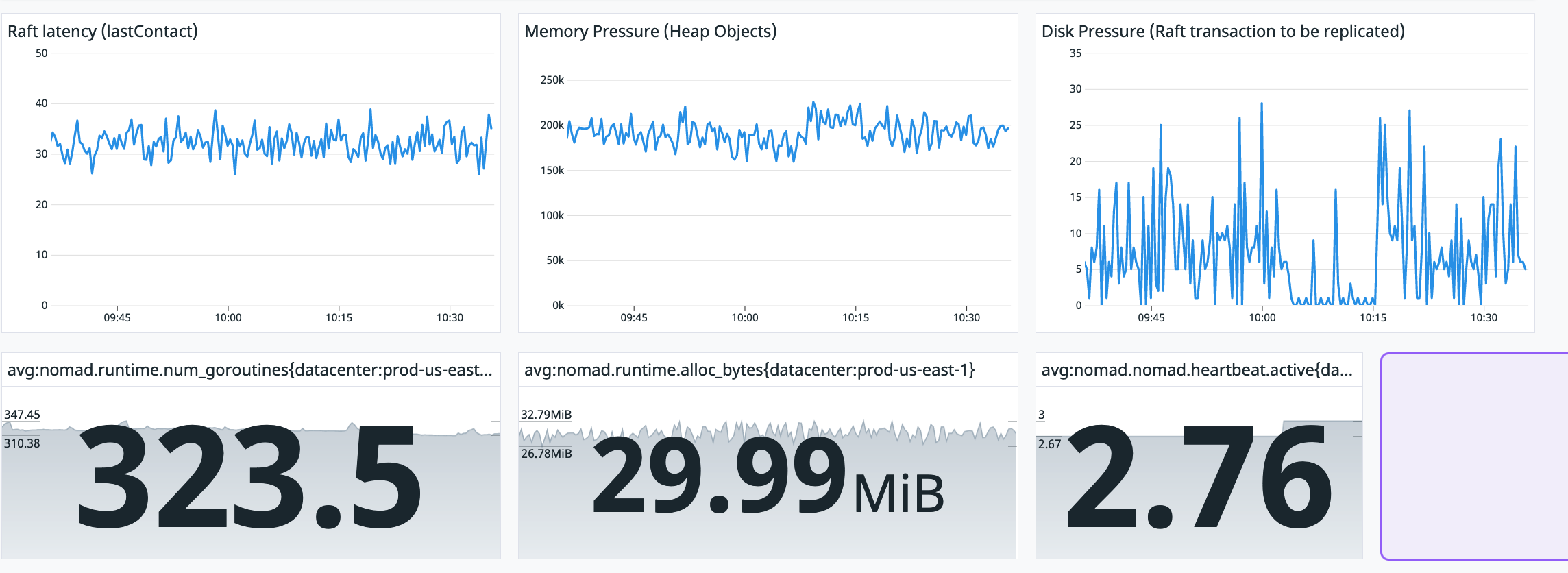
Could I please get a pointer where to look. The servers and clients seem to have spare CPU and memory.
This is a fairly small cluster with 3 servers and 9 client nodes. (16Gb RAM 4 CPUs)
Hi @vikas.saroha,
It is very hard to tell what exactly what might be causing the time duration between the task received by client and building task directory task event messages with the current information available.
increasing times to deploy jobs to a Nomad cluster
This could suggest there is something building up which is causing deployments to take longer over time. Do you have information regarding CPU, Memory, and Disk performance on clients where you are seeing this behaviour as well as logs observed when you see this?
Would it be possible to see a redacted version of the job specification which you are deploying and seeing this behaviour? This would help understand the exact sub-process being setup for the task.
Thanks,
jrasell and the Nomad team
Thanks @jrasell . We figured the problem was with the job spec - kill_timeout = "30s". This caused the new allocation to wait 30s before the old one got killed. To get around the cumulative delay we have increased max_parallel . Also using -detach option and monitoring the deployments manually at the end has brought down the deployment time significantly.