I was hoping to use nomad to run a monthly yum update and reboot.
I think I got close but I am running into an issue I need help with.
I have a shell script that calls the yum update. If the update is successful, it should reboot the machine. (see script below)
Initially, it seems to work, but after the reboot, any future yum update fails to work (preventing any future nomad executions of the script from working). The error from the subsequent yum update is:
error: rpmdb: BDB0113 Thread/process 9972/140370306357056 failed: BDB1507 Thread died in Berkeley DB library
(This error and its remedy is identified here: Fix "error: rpmdb: BDB0113 Thread/process - Thread died in Berkeley DB library | rpmdb open failed" - CentOS 7 - The Shell Guru)
Here’s my guess as to what is happening.
When the reboot command is given, Nomad thinks the task has been interrupted. Thus either as the computer shuts down or as it comes back online, it is trying to run the task again – and perhaps running the task at a point when the computer is not in the proper state for such an update – and consequently it corrupts the yum database.
The reason this is my guess is because you can see below that the task actually creates two allocations. The initial attempt at 10:23-17, and then about 33 seconds later at 10:23-51 tries again.
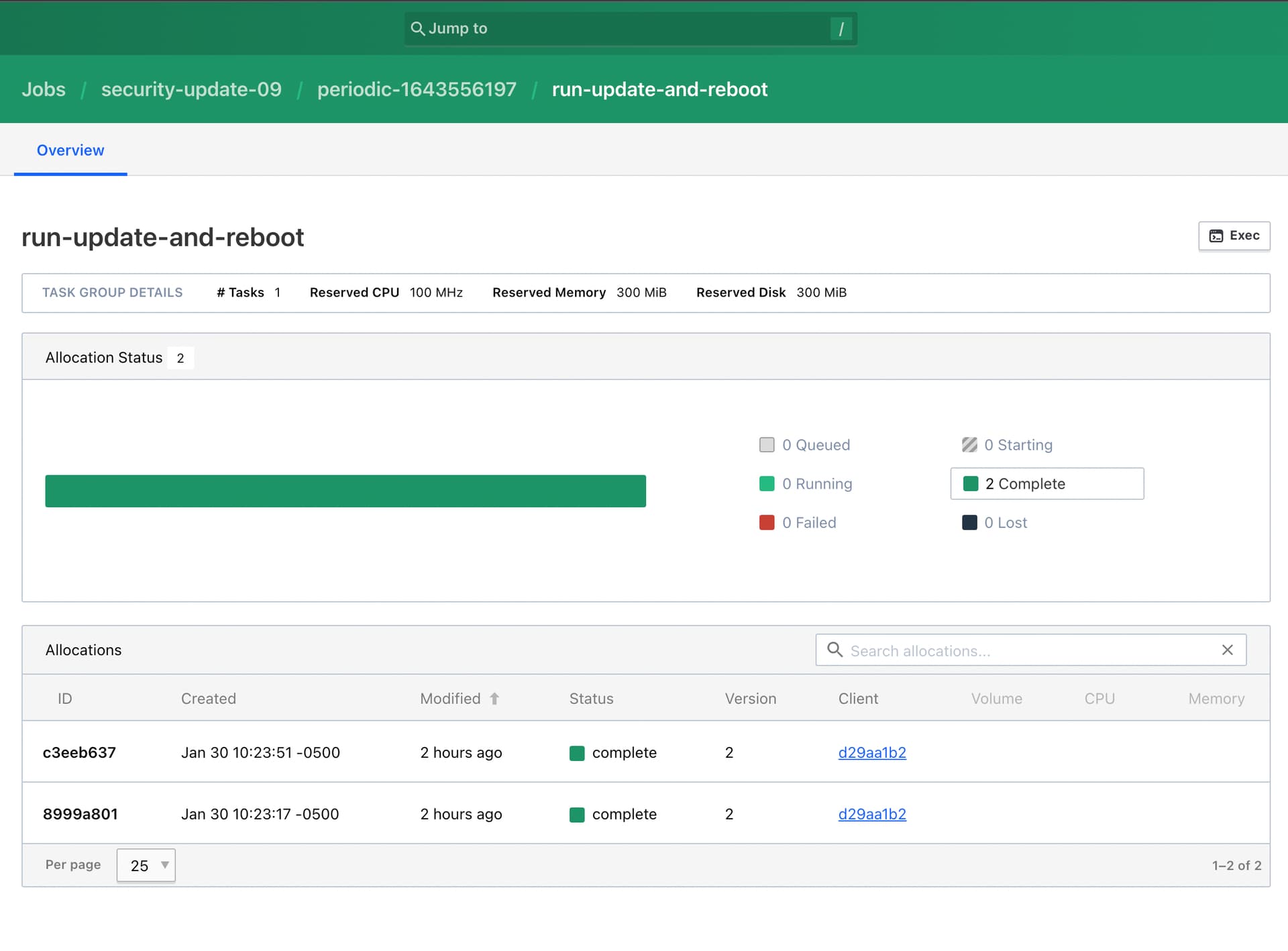
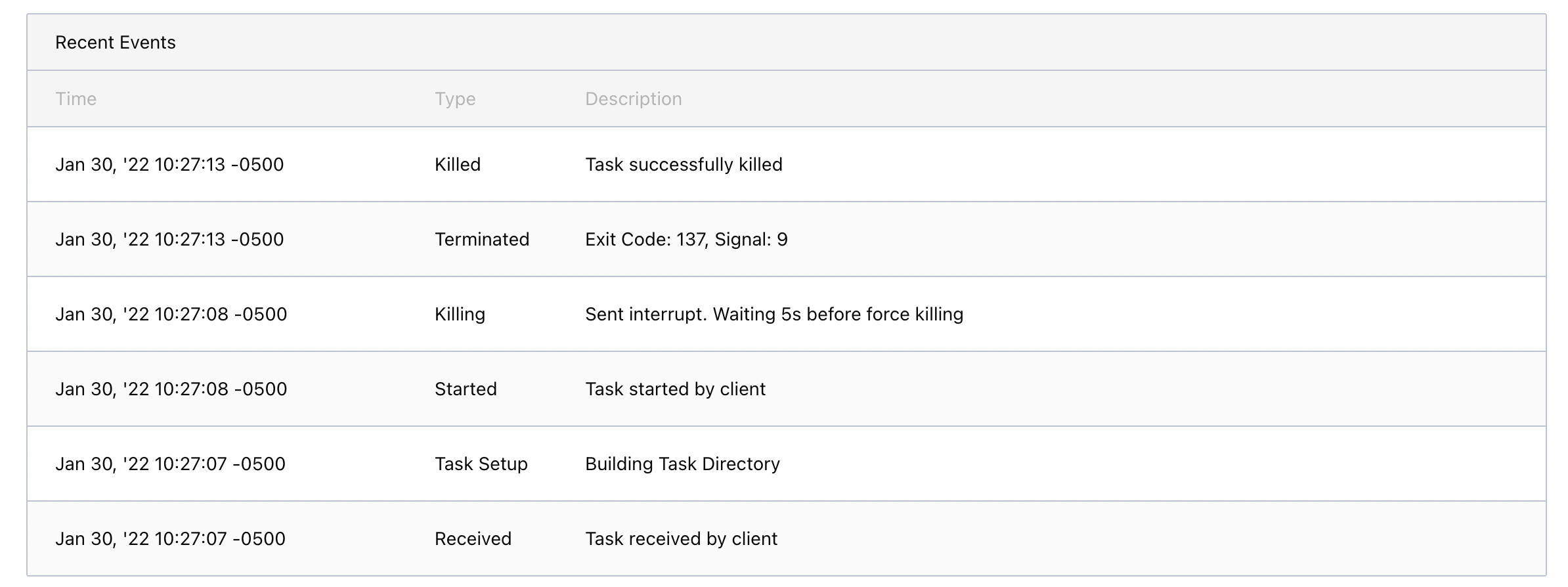
Here’s the event list for the first allocation (8999a801) of the task. You can see that it gets “interrupted” (presumably because the instance is shutting down)

And here you can see that it sort of starts again (c3eeb637). It seems to be creating the allocation at 10:23-51, 2 seconds after the first allocation ends, but then executes 3 minutes later at 10:27-07 (presumably when the computer is back online) My guess is that this is where the yum db is getting corrupted.
I tried to solve this problem, by adding the following:
restart {
attempts = 0
}
to the task stanza, so that the it wouldn’t try to create an another allocation when it thinks the task has been interrupted. But adding the above stanza didn’t seem to make a difference.
However, the restart stanza also seems like an improper work around, as it would be better if nomad saw the task as successful and complete once the reboot command had been given. (Rather than simply telling it not to restart when it it thinks the task has failed).
So perhaps my most concrete question is: what’s the proper way to submit a “reboot” task command to nomad?
Below, I provide the script I want to be periodically executed (once a month), followed by the nomad job file.
security-update.sh
#!/bin/bash
echo "scheduled security update; will reboot on successful update"
echo "current date is:"
date
echo "beginning minimal security update"
yum update-minimal --security -y
if [ $? -eq 0 ]; then
echo "update succeeded; initiating reboot"
reboot
else
echo "command did not succeed; no automatic reboot"
fi
security-update-09.nomad
job "security-update-09" {
datacenters = ["dc1"]
type = "batch"
constraint {
attribute = "${attr.unique.network.ip-address}"
value = "<the-ip-of-the-instance-i'm-trying-to-update-and-reboot>"
}
periodic {
// launch on the first day of the month
cron = "0 0 1 * *"
// Do not allow overlapping runs.
prohibit_overlap = true
}
task "run-update-and-reboot" {
driver = "raw_exec"
restart {
attempts = 0
}
config {
command = "<path>/security-update.sh"
}
}
}
Many thanks for any ideas/help.


