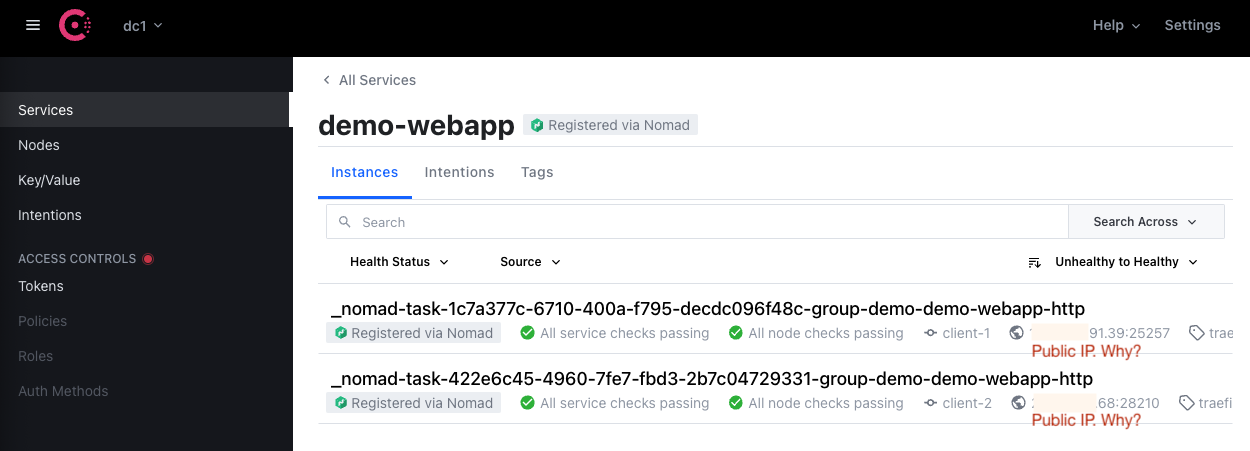
I did some experimentation with binding addresses (bind_addr) in Consul and Nomad, however, I still have the behavior of my services being registered with public IPs which is probably why I cannot reach them from inside the cluster:
How can I tell nomad or consul to map it to the private IP in the 10.0.0.0/16 network instead? The nodes are using these internal IPs just fine:
Consul servers are configured like this:
datacenter = "dc1"
data_dir = "/opt/consul"
bind_addr = "{{ GetPrivateInterfaces | include \"network\" \"10.0.0.0/16\" | attr \"address\" }}"
client_addr = "0.0.0.0"
retry_join = ["10.0.0.2", "10.0.0.3", "10.0.0.4"]
ports {
}
addresses {
}
ui = true
server = true
bootstrap_expect = 3
This is what I am using for consul clients:
datacenter = "dc1"
data_dir = "/opt/consul"
bind_addr = "{{ GetPrivateInterfaces | include \"network\" \"10.0.0.0/16\" | attr \"address\" }}"
retry_join = ["10.0.0.2", "10.0.0.3", "10.0.0.4"]
ports {
}
addresses {
}
Nomad servers have this configuration:
datacenter = "dc1"
data_dir = "/opt/nomad"
bind_addr = "{{ GetPrivateInterfaces | include \"network\" \"10.0.0.0/16\" | attr \"address\" }}"
addresses {
http = "0.0.0.0"
}
server {
enabled = true
bootstrap_expect = 3
}
Nomad clients are configured like this:
datacenter = "dc1"
data_dir = "/opt/nomad"
bind_addr = "{{ GetPrivateInterfaces | include \"network\" \"10.0.0.0/16\" | attr \"address\" }}"
addresses {
http = "0.0.0.0"
}
client {
enabled = true
}
The servers and clients have these network interfaces configured (slightly obscured with xx):
# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 96:00:01:09:xx:xx brd ff:ff:ff:ff:ff:ff
inet 49.12.xxx.xxx/32 brd 49.12.xxx.xxx scope global dynamic eth0
valid_lft 84587sec preferred_lft 84587sec
3: ens10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc pfifo_fast state UP group default qlen 1000
link/ether 86:00:00:01:9a:3f brd ff:ff:ff:ff:ff:ff
inet 10.0.0.2/32 brd 10.0.0.2 scope global dynamic ens10
valid_lft 84592sec preferred_lft 84592sec
inet6 fe80::8400:ff:fe01:9a3f/64 scope link
valid_lft forever preferred_lft forever
4: zt2lrqabin: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 2800 qdisc pfifo_fast state UNKNOWN group default qlen 1000
link/ether de:10:d0:0f:xx:xx brd ff:ff:ff:ff:ff:ff
inet 172.26.xxx.xxx/16 brd 172.26.255.255 scope global zt2lrqabin
valid_lft forever preferred_lft forever
The last one, zt2lrqabin is a ZeroTier VPN network that I am using to interact with the servers remotely which in my opinion should not matter in this context.
The nodes are connected through these routes (no route to the external 49.12.xxx.xxx network, which is what I want for security):
# ip r
default via 172.31.1.1 dev eth0
10.0.0.0/16 via 10.0.0.1 dev ens10
10.0.0.1 dev ens10 scope link
172.26.0.0/16 dev zt2lrqabin proto kernel scope link src 172.26.xxx.xxx
172.31.1.1 dev eth0 scope link
What am I missing?