We would like to update the nomad stop and restart gracefully rather than forceful kill.
Per the doc, updated the .hcl file with kill_timeout and kill_signal parameters and ran the POST to stop via API which doesnt respond or respect the SIGNAL and does a forceful kill even though it did waited for mentioned kill_timeout.
Everytime we stop , the job is getting force killed. The job post shows the updated parameters , but its not killing gracefully with submitted signal and timeout. Need your assistance to figure how to have a job gracefully stopped and started.
Thanks for the updated info. I just tried the below example jobspec locally (macOS) and the kill_signal and kill_timeout were respected as shown in the allocation details and application logs below.
Recent Events:
Time Type Description
2023-01-05T13:58:39Z Killed Task successfully killed
2023-01-05T13:58:39Z Terminated Exit Code: 0
2023-01-05T13:58:38Z Killing Sent interrupt. Waiting 25s before force killing
2023-01-05T13:57:39Z Started Task started by client
2023-01-05T13:57:39Z Task Setup Building Task Directory
2023-01-05T13:57:39Z Received Task received by client
1:M 05 Jan 2023 13:57:39.991 * Ready to accept connections
1:signal-handler (1672927118) Received SIGINT scheduling shutdown...
1:M 05 Jan 2023 13:58:38.926 # User requested shutdown...
Passing the kill_signal and kill_timeout on Job task and stopping the job via POST to the job name with updated below Job spec .
Does the running jobspec have these values also configured? If they do not, then allocations tied to this version will not observe this behaviour.
What OS are you running? I looked into Nomad’s tracked issues and found #13430 which details a known bug with kill_signal on Windows.
Thanks for your reply. Im running from mac os as well. The Job spec is seeing the updated parameters and also see message on the nomad portal with updated seconds, but the allocations seems to be killed after waiting for 25s and dont see SIGENT signal is being passed.
Could you please let me know where do you see the events for SIGENT ? I can test one more time and look for SIGENT events if thats respected ?
The kill_signal will be sent to the application at the time when the “Sent interrupt. Waiting 25s before force killing” task message is logged. If you’re trapping signals in your application, you should be able to log when a signal is triggered and view the application logs to see this. The example I have shown was using Redis and therefore the log line “Received SIGINT scheduling shutdown…” comes from the Redis server logs.
Sorry for getting back late to this. I could see the message that the Kill_signal sent interrupt on the nomad UI but dont see any logs on the nomad allocations about the signals.
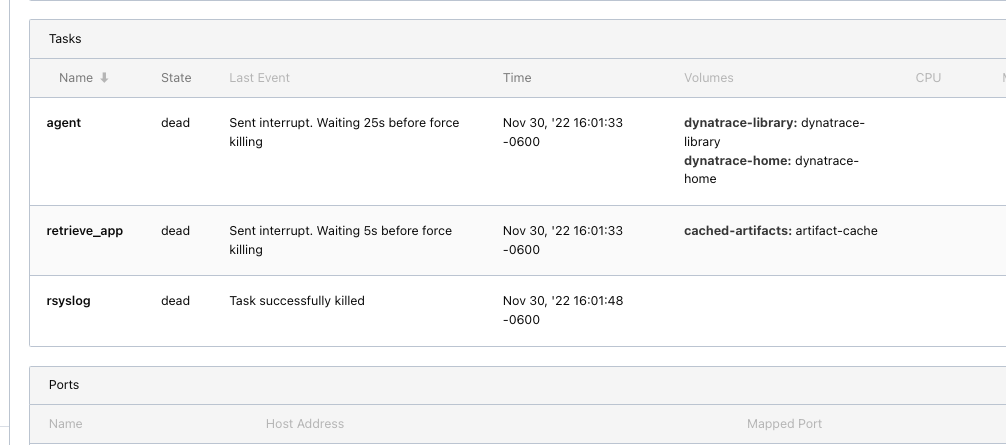
Attached some of the screenshots which shows the nomad UI has been killed after the specified kill_timeout and updated job spec with kill_signal and kill_timeout .
I dont know why and what is missing here which doesnt stop the allocations gracefully.
Please let me know if you need more details.
Here is the logs from apps which doesnt have much details. Do you know how nomad prints those signals ? Is there anything needs to be enabled to see those startup logs ?
Do you know how nomad prints those signals ? Is there anything needs to be enabled to see those startup logs ?
Nomad itself wont print that log such as the example Redis I used. It would therefore be up to the application authors to log when their application receives a signal, along with what signals they are listening for.
The task events would indicate Nomad is doing what is being configured to do. Do you have access to the code of the application you’re running or the authors? You could check what signals it is listening for, and potentially add logging to aid future debugging.
Hello Nomad Team,
The app team doesnt see any logs about the signal received at app side. Is there a way to capture at OS side for nomad agents stop/ starts. For some reason , the app is not respecting the signal sent and issuing forceful kill.